I am going to explain how to aggregate test coverage report for Gradle multi-module project. For measuring test coverage, we will use JaCoCo. Example project will use TravisCI build server and will submit coverage report to Coveralls.io.
Multi-Module project is project which creates various modules in single build, typically JARs in Java world. Such project structure is handy for splitting monolithic projects into decoupled pieces. But wait a second. Didn’t Microservices fever put monoliths into architecture anti-pattern position? No, it didn’t.
Problem
We are also building monolithic application at Dotsub. Build system of our choice is Gradle and build server is TravisCI. We use Coveralls.io to store our test coverage reports. When our code-base grew to the point when we needed to separate concerns into separate modules, I ran into problems around gathering test coverage. On Coveralls.io, you can submit only one coverage report per TravisCI build. As we wanted to have whole project built with single build, our only option was merging test coverage reports for each module and submit such aggregated report.
Example Project Structure
Our example project will have 4 modules. It is hosted in this Github repository.
.
├── build.gradle
├── .coveralls.yml
├── gradlecoverage
│ ├── build.gradle
│ └── src
│ ├── main
│ │ └── java
│ │ └── net
│ │ └── lkrnac
│ │ └── blog
│ │ └── gradlecoverage
│ │ └── GradleCoverageApplication.java
│ └── test
│ └── java
│ └── net
│ └── lkrnac
│ └── blog
│ └── gradlecoverage
│ └── GradleCoverageApplicationTest.java
├── module1
│ ├── build.gradle
│ └── src
│ ├── main
│ │ └── java
│ │ └── net
│ │ └── lkrnac
│ │ └── blog
│ │ └── gradlecoverage
│ │ └── Module1Service.java
│ └── test
│ └── java
│ └── net
│ └── lkrnac
│ └── blog
│ └── gradlecoverage
│ └── Module1ServiceTest.java
├── module2
│ ├── build.gradle
│ └── src
│ ├── main
│ │ └── java
│ │ └── net
│ │ └── lkrnac
│ │ └── blog
│ │ └── gradlecoverage
│ │ └── Module2Service.java
│ └── test
│ └── java
│ └── net
│ └── lkrnac
│ └── blog
│ └── gradlecoverage
│ └── Module2ServiceTest.java
├── moduleCommon
│ ├── build.gradle
│ └── src
│ ├── main
│ │ └── java
│ │ └── net
│ │ └── lkrnac
│ │ └── blog
│ │ └── gradlecoverage
│ │ └── CommonService.java
│ └── test
│ └── java
│ └── net
│ └── lkrnac
│ └── blog
│ └── gradlecoverage
│ └── CommonServiceTest.java
├── settings.gradle
└── .travis.ymlThere is main module gradlecoverage, which is dependent on module1 and module2. Last moduleCommon is shared dependency for module1 and module2. Each module contains simple string concatenation logic with test. The code is very basic, so we are not going to explain it here. You can inspect it on Github.
Each test intentionally doesn’t cover some test cases. This way we will prove that test coverage reports are accurate.
Module Build Script
Each module has very simple build script. Example of module1/gradle.properties follows:
jar {
baseName = 'module1'
}
dependencies {
compile project(':moduleCommon')
}The script just defines JAR module name and imports other module as dependency. Other scripts have very similar build scripts.
Main Build Script
First of all we need to import all sub-modules in settings.properties:
include 'moduleCommon'
include 'module1'
include 'module2'
include 'gradlecoverage'In main script we will apply jacoco and coveralls plugins. JaCoCo plugin will be needed for aggregating coverage reports form sub-modules. We will create custom task for aggregation. Coveralls plugin will submit aggregated report to Coveralls.io.
plugins {
id 'jacoco'
id 'com.github.kt3k.coveralls' version '2.6.3'
}
repositories {
mavenCentral()
}Next we configure Java and import dependencies for sub-modules in subprojects section:
subprojects {
repositories {
mavenCentral()
}
apply plugin: 'java'
apply plugin: "jacoco"
group = 'net.lkrnac.blog'
version = '1.0-SNAPSHOT'
sourceCompatibility = JavaVersion.VERSION_1_8
targetCompatibility = JavaVersion.VERSION_1_8
dependencies {
testCompile("junit:junit:4.12")
}
}For each sub-module, Java plugin will build JAR artifact. Each module is tested by JUnit framework. Test coverage is measured by JaCoCo plugin.
Aggregate Test Coverage Reports
Last piece of build configuration will aggregate test coverage reports:
def publishedProjects = subprojects.findAll()
task jacocoRootReport(type: JacocoReport, group: 'Coverage reports') {
description = 'Generates an aggregate report from all subprojects'
dependsOn(publishedProjects.test)
additionalSourceDirs = files(publishedProjects.sourceSets.main.allSource.srcDirs)
sourceDirectories = files(publishedProjects.sourceSets.main.allSource.srcDirs)
classDirectories = files(publishedProjects.sourceSets.main.output)
executionData = files(publishedProjects.jacocoTestReport.executionData)
doFirst {
executionData = files(executionData.findAll { it.exists() })
}
reports {
html.enabled = true // human readable
xml.enabled = true // required by coveralls
}
}
coveralls {
sourceDirs = publishedProjects.sourceSets.main.allSource.srcDirs.flatten()
jacocoReportPath = "${buildDir}/reports/jacoco/jacocoRootReport/jacocoRootReport.xml"
}
tasks.coveralls {
dependsOn jacocoRootReport
}First we read all sub-modules into publishedProjects variable. After that we define custom aggregation jacocoRootReport task. It is inherited from JacocoReport task type. This task will be dependent on test task of each module from publishedProjects. This makes sure that test coverage reports for sub-modules are gathered for aggregation before jacocoRootReport is executed. Next we configure necessary directories for JaCoCo engine and gather all execution data from sub-modules.
Lastly we configure what kind of output we want to generate. Configuration xml.enabled = true will create aggregated report which will be submitted to Coveralls.io via coveralls task.
TravisCI Manifest
TravisCI Manifest (.travis.yml) file configure Java environment and runs single command to build and submit aggregated test coverage report by executing coveralls task:
language: java
jdk:
- oraclejdk8
install: echo "skip './gradlew assemble' step"
script: ./gradlew build coveralls --continueCoveralls Manifest
To be able to submit report to coveralls, we need to define Coveralls.io repository token in file .coveralls.yml:
repo_token: JQofR7TNqCMebvHgE8wHwF6rznjvEc0FrFinal Report
Final report can be found here:
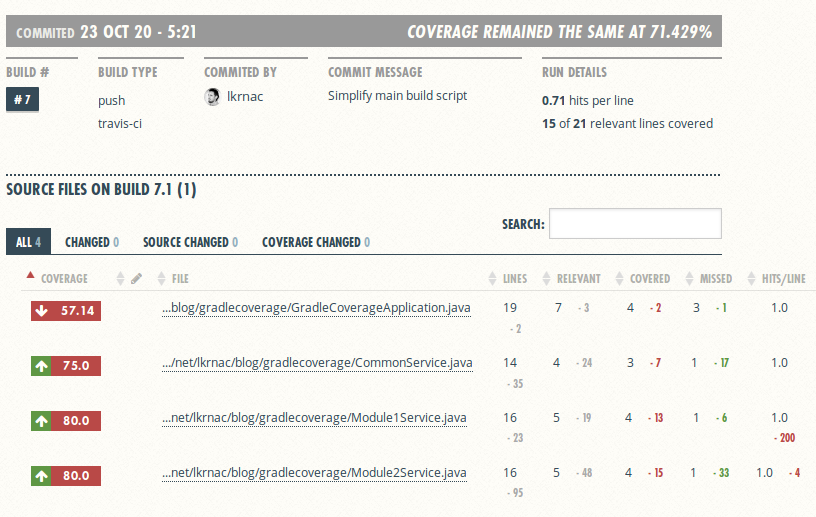
As you can see, there are all classes from separate modules. The only problem is that we can’t fond which module class belong to from such coverage report. But it’s not a big deal to me.
Credits
Custom aggregation task was inspired by build script for Caffeine project. It is caching library.